
_2800.webp "پردرآمدترین شاخه و رشته مهندسی هوافضا")
مهندسی هوافضا یکی از پیشرفتهترین و چالشبرانگیزترین رشتههای مهندسی است که به طراحی، تحلیل و بهینهسازی وسایل پروازی مانند هواپیماها، فضاپیماها، پهپادها و موشکها میپردازد. این حوزه با ترکیب علوم مهندسی، فیزیک، ریاضیات و فناوریهای نوین، نقش اساسی در توسعه صنعت هوانوردی و فضایی ایفا میکند. در دنیای امروز، کشورهایی که در این زمینه پیشرفت کردهاند، نهتنها از نظر فناوری برتری دارند، بلکه از نظر اقتصادی نیز به سودآوری بالایی دست یافتهاند.
با توجه به رشد سریع فناوریهای هوایی و فضایی، نیاز به متخصصان این حوزه بیش از گذشته احساس میشود. از سوی دیگر، عوامل متعددی مانند گرایش تحصیلی، تجربه کاری، مهارتهای تخصصی و نوع صنعت، تأثیر مستقیم بر سطح درآمد مهندسان هوافضا دارند. به همین دلیل، بسیاری از دانشجویان و فعالان این حوزه به دنبال شناخت پردرآمدترین شاخه و رشته مهندسی هوافضا هستند تا مسیر شغلی خود را بهگونهای انتخاب کنند که علاوه بر علاقه، بازده مالی مناسبی نیز داشته باشد. در این مقاله، به بررسی گرایشهای مختلف مهندسی هوافضا، مهارتهای کلیدی، فرصتهای شغلی و تأثیر تجربه و تحصیلات بر میزان درآمد این مهندسان پرداختهایم.
فهرست مطالب:
- معرفی مهندسی هوافضا و اهمیت آن در صنعت
- بررسی گرایشهای مختلف مهندسی هوافضا
- تأثیر تخصصهای مختلف بر درآمد مهندسان هوافضا
- مقایسه درآمد مهندسان هوافضا در صنایع مختلف
- نقش تجربه و تحصیلات تکمیلی در افزایش درآمد
- فرصتهای شغلی و بازار کار برای مهندسان هوافضا
- مهارتهای مورد نیاز برای دستیابی به درآمد بالاتر در مهندسی هوافضا
- نتیجه گیری
معرفی مهندسی هوافضا و اهمیت آن در صنعت
مهندسی هوافضا شاخهای از مهندسی است که به مطالعه، طراحی و ساخت وسایل پرنده مانند هواپیما، هلیکوپتر، موشک و فضاپیما میپردازد. این رشته ترکیبی از علوم مهندسی مکانیک، الکترونیک، فیزیک و ریاضیات است و به عنوان یکی از پیشرفتهترین و جذابترین رشتههای مهندسی شناخته میشود.
اهمیت مهندسی هوافضا در صنعت به دلیل نقش کلیدی آن در توسعه فناوریهای پیشرفته و کاربردهای گسترده در حملونقل هوایی، فضایی و نظامی است. مهندسان هوافضا با طراحی و بهبود سیستمهای پروازی، به افزایش ایمنی، کارایی و کاهش هزینهها کمک میکنند. همچنین، این رشته در توسعه فناوریهای نوینی مانند پهپادها و ماهوارهها نقش بسزایی دارد.
در میان گرایشهای مختلف این رشته، آیرودینامیک به عنوان یکی از پردرآمدترین شاخهها شناخته میشود. مهندسان آیرودینامیک با تحلیل و بهینهسازی جریان هوا در اطراف وسایل پرنده، به بهبود عملکرد و کارایی آنها میپردازند. این تخصص در صنایع هواپیماسازی و خودروسازی بسیار مورد توجه است و فرصتهای شغلی متعددی را ارائه میدهد.
با توجه به رشد روزافزون صنعت هوافضا و نیاز به تخصصهای مرتبط، مهندسی هوافضا به عنوان یکی از رشتههای با آینده شغلی روشن و درآمد مناسب محسوب میشود. فارغالتحصیلان این رشته میتوانند در حوزههای مختلفی مانند طراحی و ساخت هواپیما، فضاپیما، سیستمهای دفاعی و تحقیق و توسعه فعالیت کنند.
بررسی گرایشهای مختلف مهندسی هوافضا
مهندسی هوافضا شامل گرایشهای متنوعی است که هر یک به جنبههای خاصی از طراحی، ساخت و تحلیل وسایل پرنده میپردازند.ز جمله این گرایشها میتوان به آیرودینامیک، جلوبرندگی، دینامیک پرواز و کنترل، سازههای هوایی و مهندسی فضایی اشاره کرد. آیرودینامیک ه مطالعه نیروها و گشتاورهای وارد بر اجسام در حال حرکت در سیالات میپردازد و در طراحی هواپیماها و فضاپیماها نقش اساسی دارد. جلوبرندگی تمرکز بر طراحی و تحلیل سیستمهای پیشرانه مانند موتورهای جت و راکت است که تأمین نیروی لازم برای حرکت وسایل پرنده را بر عهده دارند. دینامیک پرواز و کنترل به بررسی رفتار و پایداری وسایل پرنده در طول پرواز و طراحی سیستمهای کنترلی مرتبط میپردازد. سازههای هوایی در طراحی و تحلیل ساختارهای مقاوم و سبک برای هواپیماها و فضاپیماها تمرکز دارد تا استحکام لازم در برابر بارهای مختلف را فراهم کند. مهندسی فضایی ه مطالعه و توسعه سیستمهای فضایی مانند ماهوارهها و فضاپیماها میپردازد و شامل مباحثی چون طراحی مدار و سیستمهای ارتباطی است. از میان این گرایشها، جلوبرندگی به عنوان یکی از پردرآمدترین شاخههای مهندسی هوافضا شناخته میشود، زیرا توسعه و بهبود سیستمهای پیشرانه در صنایع هوایی و فضایی از اهمیت بالایی برخوردار است و نیاز به تخصص و دانش فنی عمیقی دارد.
.webp)
|
گرایش |
توضیحات |
|
آیرودینامیک |
مطالعه جریان هوا و تأثیر آن بر اجسام متحرک مانند هواپیماها و موشکها. این گرایش به تحلیل و طراحی اجسام پرنده با هدف بهبود کارایی و کاهش مقاومت هوا میپردازد. |
|
پیشرانش (جلوبرندگی) |
بررسی و طراحی سیستمهای پیشرانش مانند موتورهای جت و راکتها. هدف این گرایش، بهبود کارایی و قدرت پیشرانش وسایل پرنده است. |
|
دینامیک پرواز و کنترل |
مطالعه رفتار و حرکت وسایل پرنده و توسعه سیستمهای کنترلی برای بهبود پایداری و هدایت آنها. این گرایش به تحلیل و طراحی سیستمهای کنترلی پیشرفته میپردازد. |
|
سازههای هوایی |
طراحی و تحلیل سازههای مورد استفاده در وسایل پرنده، با تمرکز بر استحکام، سبکی و مقاومت در برابر شرایط محیطی. این گرایش به بهینهسازی مواد و ساختارها میپردازد. |
|
مهندسی فضایی |
طراحی و توسعه سیستمهای فضایی مانند ماهوارهها و فضاپیماها. این گرایش به تحلیل و طراحی سیستمهای پیچیده برای عملیات در فضا میپردازد. |
تأثیر تخصصهای مختلف بر درآمد مهندسان هوافضا
تخصصهای مختلف در مهندسی هوافضا تأثیر مستقیمی بر میزان درآمد مهندسان این حوزه دارند.هطور کلی، مهندسی هوافضا به گرایشهایی مانند آیرودینامیک، پیشرانش، دینامیک پرواز و کنترل، سازههای هوایی و مهندسی فضایی تقسیم میشود.در میان این تخصصها، گرایش پیشرانش که به طراحی و توسعه موتورهای جت و راکت میپردازد، به دلیل پیچیدگی و اهمیت بالای آن در صنعت هوافضا، از بازار کار مناسبی برخوردار است. همچنین، گرایش آیرودینامیک که به مطالعه جریان هوا و اثر آن بر اجسام متحرک میپردازد، در طراحی بهینه وسایل پرنده نقش کلیدی دارد و میتواند فرصتهای شغلی مناسبی را فراهم کند. با توجه به نیاز روزافزون به فناوریهای فضایی، گرایش مهندسی فضایی نیز اهمیت بیشتری پیدا کرده و متخصصان این حوزه در پروژههای مرتبط با ماهوارهها و فضاپیماها مشارکت میکنند. بهطور کلی، پردرآمدترین شاخه و رشته مهندسی هوافضا بسته به تقاضای بازار و پروژههای موجود میتواند متفاوت باشد، اما تخصص در حوزههای پیشرانش و آیرودینامیک (Aerodynamics) به دلیل کاربردهای گسترده و نیاز صنعت، میتواند به درآمدهای بالاتری منجر شود.
مقایسه درآمد مهندسان هوافضا در صنایع مختلف
.webp)
درآمد مهندسان هوافضا بسته به صنعتی که در آن فعالیت میکنند، متفاوت است. در کشورهای توسعهیافته، این رشته جزو پردرآمدترین شاخههای مهندسی محسوب میشود. به عنوان مثال، در ایالات متحده، متوسط درآمد سالانه مهندسان هوافضا در سال ۲۰۱۳ حدود ۱۰۲,۱۰۰ دلار بوده است. در ایران، بازار کار مهندسی هوافضا محدودتر است و فرصتهای شغلی عمدتاً در صنایع دفاعی، هوایی و خودروسازی متمرکز هستند. با این حال، با توسعه پروژههای فضایی و هوایی در کشور، نیاز به مهندسان هوافضا افزایش یافته و فرصتهای شغلی متنوعتری ایجاد شده است
به طور کلی، درآمد مهندسان هوافضا در ایران با توجه به تجربه، تخصص و صنعتی که در آن فعالیت میکنند، متفاوت است. با افزایش تجربه و مهارت، درآمد این مهندسان نیز بهبود مییابد.
در نتیجه، انتخاب شاخه و صنعتی که مهندس هوافضا در آن فعالیت میکند، تأثیر مستقیمی بر میزان درآمد او دارد. بنابراین، برای دستیابی به پردرآمدترین شاخه و رشته مهندسی هوافضا، انتخاب حوزهای با تقاضای بالا و فرصتهای شغلی مناسب اهمیت دارد.
نقش تجربه و تحصیلات تکمیلی در افزایش درآمد
تجربه و تحصیلات تکمیلی نقش بسزایی در افزایش درآمد مهندسان هوافضا دارند. مهندسان با تجربه بالاتر، به دلیل تسلط بیشتر بر مهارتها و دانش فنی، معمولاً درآمد بالاتری نسبت به همتایان کمتجربه خود دارند. بهعنوان مثال، در ایران، مهندسان هوافضا با سابقه کاری بیش از ۷ سال، درآمدی بیش از ۲۱,۶۰۰,۰۰۰ تومان در ماه دارند، در حالی که این مقدار برای مهندسان تازهکار کمتر از ۳ سال تجربه، حدود ۱۲,۵۰۰,۰۰۰ تومان است. تحصیلات تکمیلی نیز تأثیر قابلتوجهی بر افزایش درآمد دارد. فارغالتحصیلان مقاطع کارشناسی ارشد و دکتری، به دلیل تخصص و دانش عمیقتر، فرصتهای شغلی بهتری را در صنایع هوافضا به دست میآورند که منجر به افزایش درآمد میشود. در کانادا، شرکتهای هوافضا به دنبال مهندسان با تجربه و تحصیلات بالا هستند و از سوی دیگر، دانشجویان بینالمللی نیز میتوانند از برنامههای تحصیلی و کاری برای ورود به این صنعت بهره ببرند. بنابراین، ترکیب تجربه کاری و تحصیلات تکمیلی میتواند مسیر پیشرفت شغلی و افزایش درآمد را برای مهندسان هوافضا هموار کند.
بیشتر بخوانید: بهترین دانشگاه های مهندسی هوافضا
فرصتهای شغلی و بازار کار برای مهندسان هوافضا
.webp)
مهندسی هوافضا یکی از رشتههای مهندسی است که فرصتهای شغلی متنوعی را در صنایع مختلف ارائه میدهد.
- حوزههای فعالیت مهندسان هوافضا:
طراحی و ساخت هواپیما، فضاپیما، موشک، ماهواره و سایر وسایل پرنده.
توسعه و ارتقای سیستمهای پیشرانش، هدایت، ناوبری و کنترل هواپیما و فضاپیما.
- بازار کار مهندسی هوافضا در ایران:
با توجه به رشد صنعت هوافضا و نیاز روزافزون به متخصصان، بازار کار مناسبی برای مهندسان هوافضا وجود دارد.
زمینههای شغلی شامل:
هواپیماسازی
صنعت فضایی
صنعت دفاعی
سازمانهای دولتی
مؤسسات تحقیقاتی
- درآمد مهندسان هوافضا در ایران:
مهندسان هوافضا در زمره مهندسان پردرآمد کشور قرار دارند.
میانگین حقوق در سال ۱۴۰۱ حدود ۱۵ تا ۲۵ میلیون تومان بوده است.
- فرصتهای شغلی بینالمللی:
مهندسان هوافضا میتوانند در شرکتهای بزرگی مانند ناسا، اسپیسایکس، بوئینگ و ایرباس مشغول به کار شوند.
درآمد در کشورهای توسعهیافته:
در ایالات متحده آمریکا، درآمد سالانه بین ۵۸,۰۰۰ تا ۱۰۷,۰۰۰ دلار است.
- چالشهای بازار کار مهندسی هوافضا:
رقابت شدید برای ورود به بازار کار.
نیاز به مطالعه و یادگیری مداوم.
محدودیت فرصتهای شغلی در برخی کشورها.
مهندسی هوافضا با ارائه فرصتهای شغلی متنوع و درآمد مناسب، یکی از رشتههای جذاب برای علاقهمندان به این حوزه محسوب میشود.
مهارتهای مورد نیاز برای دستیابی به درآمد بالاتر در مهندسی هوافضا
.webp)
برای دستیابی به درآمد بالاتر در مهندسی هوافضا، تسلط بر مهارتهای تخصصی و نرمافزاری ضروری است. مهارتهای تحلیلی قوی، توانایی حل مسائل پیچیده و دانش عمیق در ریاضیات و فیزیک از جمله این مهارتها هستند. همچنین، آموزش کتیا، آموزش متلب و آموزش انسیس می تواند به طراحی و شبیهسازی سیستمهای هوافضا کمک کند.
- مهارتهای تخصصی و تحلیلی:
تسلط بر مهارتهای تحلیلی قوی، توانایی حل مسائل پیچیده و دانش عمیق در ریاضیات و فیزیک از جمله الزامات اصلی برای موفقیت در این رشته است.
- آشنایی با نرمافزارهای طراحی و تحلیل:
نرمافزارهایی مانند MATLAB، CATIA و ANSYS برای طراحی و شبیهسازی سیستمهای هوافضا ضروری هستند و تسلط بر آنها میتواند شانس دستیابی به درآمد بالاتر را افزایش دهد.
- مهارتهای نرم:
کار تیمی: توانایی همکاری مؤثر با تیمهای چندرشتهای در پروژههای بزرگ.
مهارتهای ارتباطی: توانایی انتقال ایدهها و هماهنگی با همکاران و مشتریان.
مدیریت پروژه: برنامهریزی، اولویتبندی و مدیریت پروژههای پیچیده هوافضا.
بهروز بودن و آگاهی از پیشرفتهای صنعت:
آگاهی از جدیدترین فناوریها و نوآوریها در صنعت هوافضا باعث میشود مهندسان در بازار کار رقابتیتر شوند و درآمد بالاتری داشته باشند.
- تسلط بر زبان انگلیسی:
زبان انگلیسی بهعنوان زبان بینالمللی علم و فناوری، برای مطالعه منابع تخصصی، ارتباط با همکاران بینالمللی و مشارکت در پروژههای جهانی ضروری است.
با ترکیب این مهارتها، مهندسان هوافضا میتوانند به پردرآمدترین موقعیتهای شغلی در این رشته دست یابند.
نتیجه گیری
نتیجهگیری در مورد مهندسی هوافضا نشان میدهد که این رشته با تمام چالشها و پیچیدگیهای خود، یکی از پردرآمدترین و نوآورانهترین حوزههای مهندسی است که همواره در حال تحول و پیشرفت است. با توجه به نیاز روزافزون به فناوریهای هوایی و فضایی، فرصتهای شغلی برای مهندسان هوافضا روز به روز در حال گسترش است و از طرفی، متخصصانی که توانایی ترکیب مهارتهای فنی با خلاقیت و نوآوری دارند، میتوانند به موفقیتهای چشمگیری دست یابند.
انتخاب گرایش مناسب، تحصیلات تکمیلی، کسب تجربه و ارتقاء مهارتهای تخصصی از جمله عواملی هستند که میتوانند به طور مستقیم بر درآمد مهندسان هوافضا تأثیرگذار باشند. همچنین، توجه به پردرآمدترین شاخه و رشته مهندسی هوافضا میتواند کمک بزرگی به تصمیمگیری آگاهانه در انتخاب مسیر شغلی و دستیابی به فرصتهای اقتصادی بیشتر باشد. در نهایت، مهندسان هوافضا با سرمایهگذاری بر دانش، مهارتها و تجربه خود میتوانند نقش مؤثری در پیشرفت صنعت هوافضا و ایجاد فرصتهای شغلی جدید ایفا کنند و به موفقیتهای بینالمللی دست یابند.
نویسنده: محمد حسن بهزادی، کارشناسی عمران
_2800.webp "مزایا و معایب رشته ی مهندسی پزشکی")
.webp)
.webp)
.webp)
.webp)
_2800.webp "افراد موفق در رشته مهندسی مواد")
.webp)
.webp)
.webp)

.webp)
.webp)
_2800.webp "پردرآمدترین رشته مهندسی در ایران و جهان")
.webp)
.webp)
.webp)
_2800.webp "پردرآمدترین شاخه و رشته مهندسی نفت")
.webp)
.webp)
.webp)
_2800.webp "بهترین دانشگاه های ایران برای اپلای")
.webp)
.webp)
.webp)
.webp)
.webp)
.webp)
.webp)
.webp)
_2800.webp "پردرآمدترین شاخهها و رشتههای مهندسی شیمی")
.webp)

.webp)
.webp)
.webp)
.webp)
_2800.webp "مهندسی صنایع بهتر است یا مهندسی مکانیک؟")
.webp)
.webp)
.webp)
.webp)
_2800.webp "مهندسی هوافضا چیست؟ (گرایش ها، بازار کار و درآمد)")
.webp)
.webp)
.webp)
_2800.webp "پردرآمدترین گرایش مهندسی مکانیک")
.webp)
.webp)
.webp)
.webp)
.webp)
_2800.webp "افراد موفق در رشته مهندسی برق")
.webp)
.webp)
.webp)
.webp)
.webp)
.webp)
.webp)
.webp)
_2800.webp "مهندسی عمران یا مکانیک: کدام یک برای آینده شغلی بهتر است؟")
.webp)
.webp)
_2800.webp "مهندسی مکانیک چیست؟ (گرایش ها، بازار کار و درآمد)")
.webp)
.webp)
.webp)
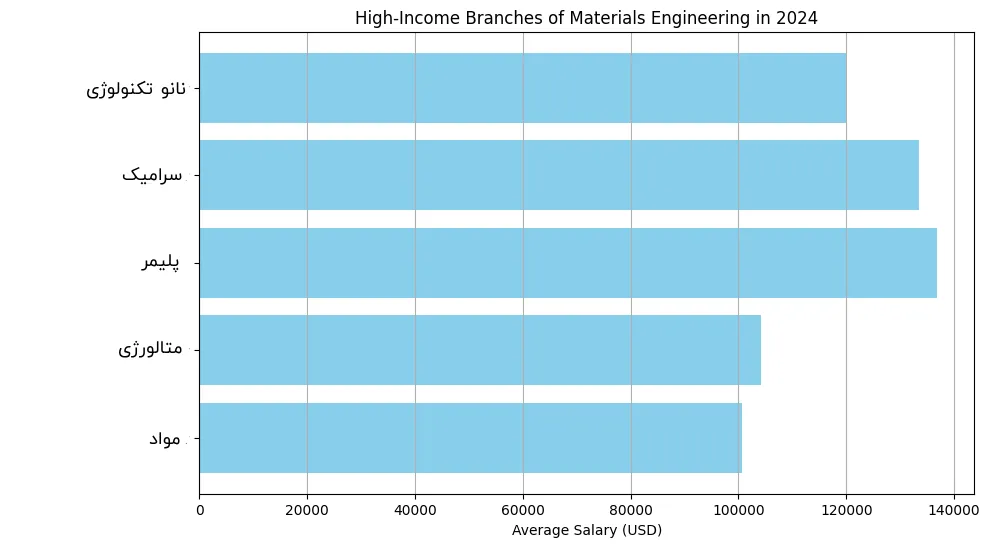
_2800.webp "پردرآمدترین شاخه و رشته مهندسی مواد")
.webp)
.webp)
.webp)
_2800.webp "پردرآمدترین شاخه و رشته مهندسی معماری")
.webp)
.webp)
_2800.webp "پردرآمد ترین گرایش در مهندسی برق")
.webp)
.webp)
.webp)







